
티스토리 뷰
ajax로 받은 OpenAPI 데이터에서 별점의 개수는 Sting요소가 아닌 숫자 요소로 받아야했기 때문에 받은 숫자에 따라 평점별 개수를 출력하는 작업을 따로 추가해줬어야 했다.
let stars = '';
for (let j = 0; j < star; j++) {
stars += '⭐';
}이 작업을 위해 위와 같은 코드를 작성했는데 더 간단한
let stars = '⭐'.repeat(star);repeat() 함수가 존재했다.
Python을 이용한 크롤링
크롤링(crawling)이란?
- Web상에 존재하는 Contents를 수집하는 작업(프로그래밍으로 자동화 가능)
- HTML 페이지를 가져와서 HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법
- Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서, 받은 데이터 중 필요한 데이터만 추출하는 기
- Selenium등 브라우저를 프로그래밍으로 조작해서, 필요한 데이터만 추출하는 기법
출처: 잔재미코딩(https://www.fun-coding.org/crawl_basic2.html)
네이버 영화 랭킹을 크롤링하는 작업을 한다. Python의 BeautifulSoup 라이브러리를 사용해서 영화 랭킹 정보를 가져오는 작업을 수행했다.
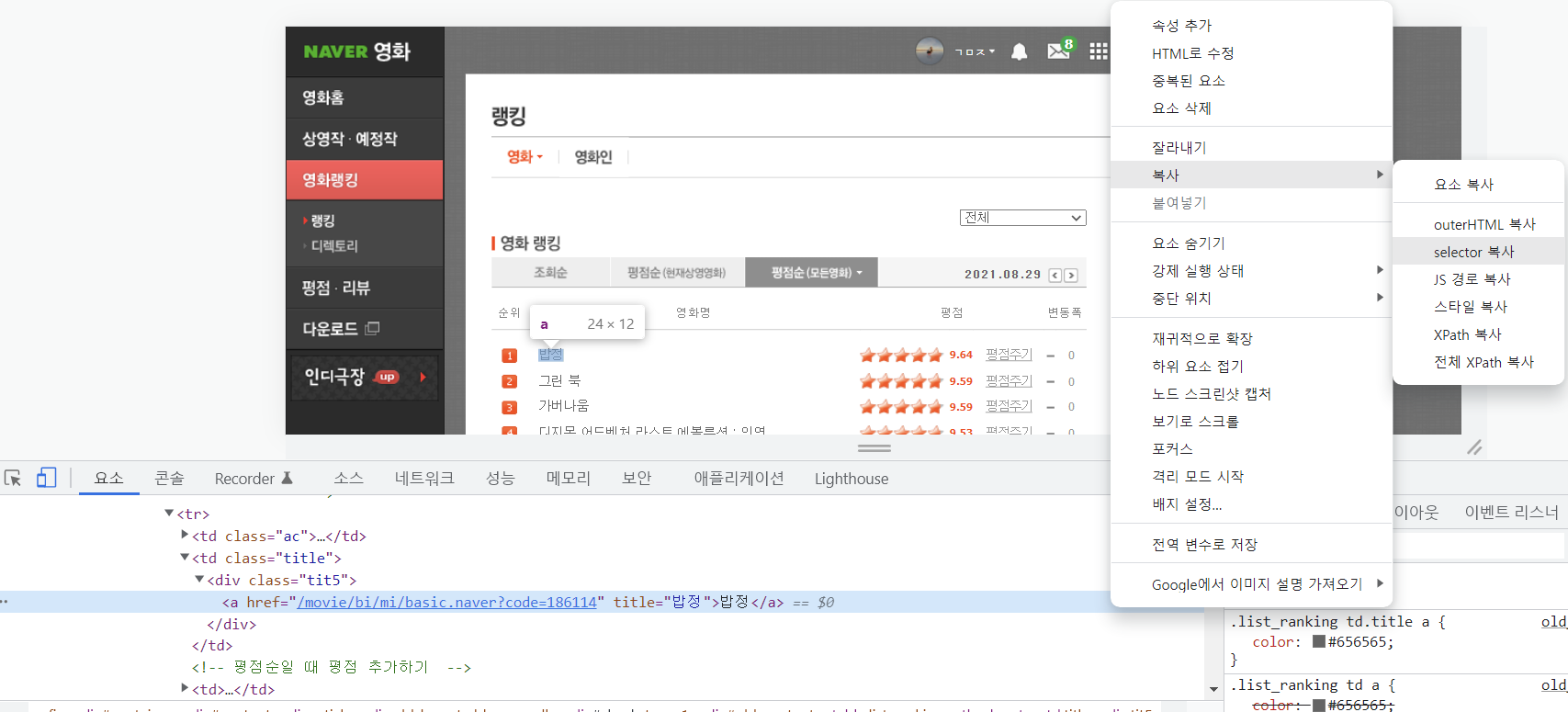
위처럼 요소에서 값을 받고 싶은 요소에 커서를 올리고 오른쪽 마우스 검사 - 복사 - selector 복사를 하게 되면
# old_content > table > tbody > tr:nth-child(3) > td.title > div > a이런식으로 복사가 되는데, 영화 제목, 순위, 별점을 포함하는 태그들을 soup.select()를 이용해서
movies = soup.select("#old_content > table > tbody > tr")와 같이 잡은 것은 좋았으나 자꾸 AttributeError: 'NoneType' object has no attribute 'text' / ('img')['alt']등과 같은 에러가 발생했다.
for movie in movies:
title = movie.select_one('td.title > div > a').text
print(title)
이게 자꾸 해결이 안돼서 시간을 많이 잡아먹었다. title = movie.select_one('td.title > div > a')를 잡고 출력을 하면 구분선의 값이 None으로 할당된 것을 확인할 수 있는데, 이 구분선 때문에 AttributeError가 발생한 것이었다.
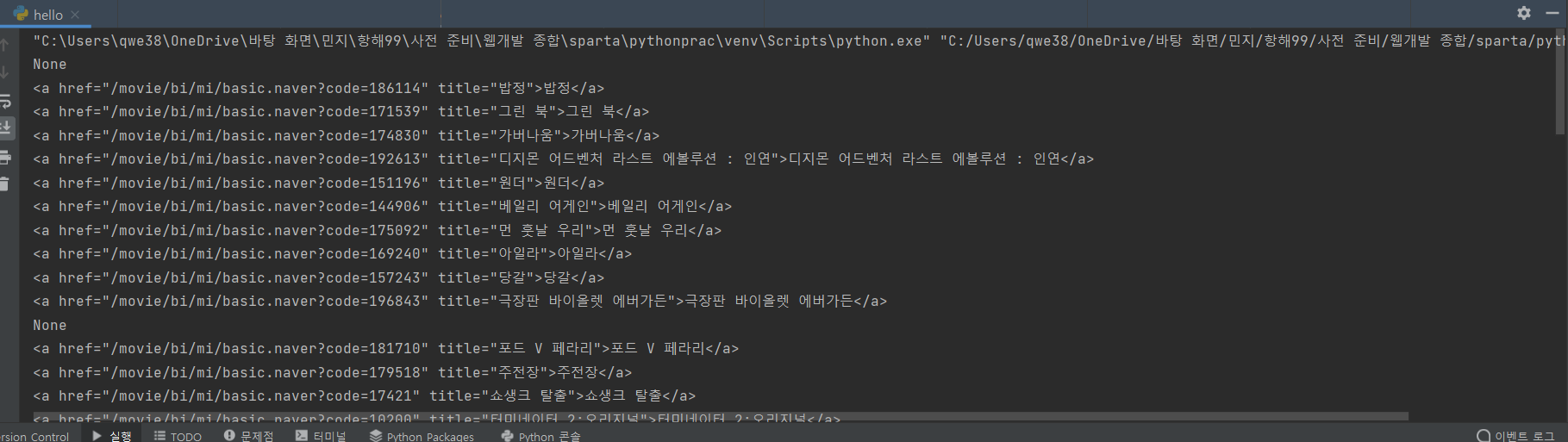
따라서 구분선을 예외처리를 해주고 작업을 했어야 했다.
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('img')['alt']
point = movie.select_one('td.point').text
print(rank, title, point)지니뮤직 크롤링
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&rtm=Y', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select("#body-content > div.newest-list > div > table > tbody > tr")
for song in songs:
title_space = song.select_one('td.info > a.title.ellipsis')
title = title_space.text.strip()
rank_space = song.select_one('td.number').text
rank = rank_space[0:2].strip()
artist = song.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)크롤링을 하니 공백이 너무 많이 나와서 내장함수안 strip()과 list[index:index]를 사용했다. songs 리스트 값에 None이 없었으므로 if문을 사용한 예외처리는 해주지 않았다.
Pymongo 라이브러리를 통한 CRUD 작업
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})이 코드들을 재사용해서 CRUD 작업을 수행한다.
모든 영화 파일 중에서 제목 가버나움과 같은 평점을 가진 영화들을 출력하는 코드를
all_movie = list(db.movies.find({},{'_id':False}))
capernaum = db.movies.find_one({'title':'가버나움'})
star_capernaum = capernaum['star']
same_star = []
for movie in all_movie:
if movie['star'] == star_capernaum:
same_star.append(movie['title'])
for title in same_star:
print(title)와 같이 작성했지만 all_movie 변수에 list(db.movies.find({'star':star}))를 할당하면 if문을 작성하지 않더라도 간단하게 조건에 맞는 리스트를 추출할 수 있었다.
capernaum = db.movies.find_one({'title':'가버나움'})
star_capernaum = capernaum['star']
all_movie = list(db.movies.find({'star':star_capernaum},{'_id':False}))
for movie in all_movie:
print(movie['title'])코드가 훨씬 더 간결하다.
'항해99(7기) > 웹개발 종합(사전준비)' 카테고리의 다른 글
| [항해99(7기)] 웹개발 종합반 4주차 (0) | 2022.04.15 |
|---|---|
| [항해99(7기)] 웹개발 종합반 2주차 (0) | 2022.04.02 |
| [항해99(7기)] 웹개발 종합반 1주차 (0) | 2022.03.29 |